
Metadata Layer Architecture of Open Table Formats
Exploring the Design and Architecture of the Metadata Layer in Modern Data Lakehouse Table Formats

Modern Open Table Formats, such as Hudi, Delta Lake, and Iceberg, are built on the foundation of a file-based metadata layer. In these formats, all metadata related to tables, columns, data files, and partitions is stored in metadata files alongside the actual data in data lakes.
In previous generation Hive-style directory-oriented table format, which I have covered their evolution in a comprehensive essay, data files and partitions were tightly coupled to the underlying physical storage system API.
The query engines relied on the file system API for listing data files and partitions each time a query was executed. Additionally, in systems like Hive an external Metastore is employed for keeping track of metadata such as table partitions.
The modern data lakehouse engines represents an alternative mechanism for implementing table formats in cloud storage systems. Modern table formats maintain the entire table state within log-oriented metadata files.
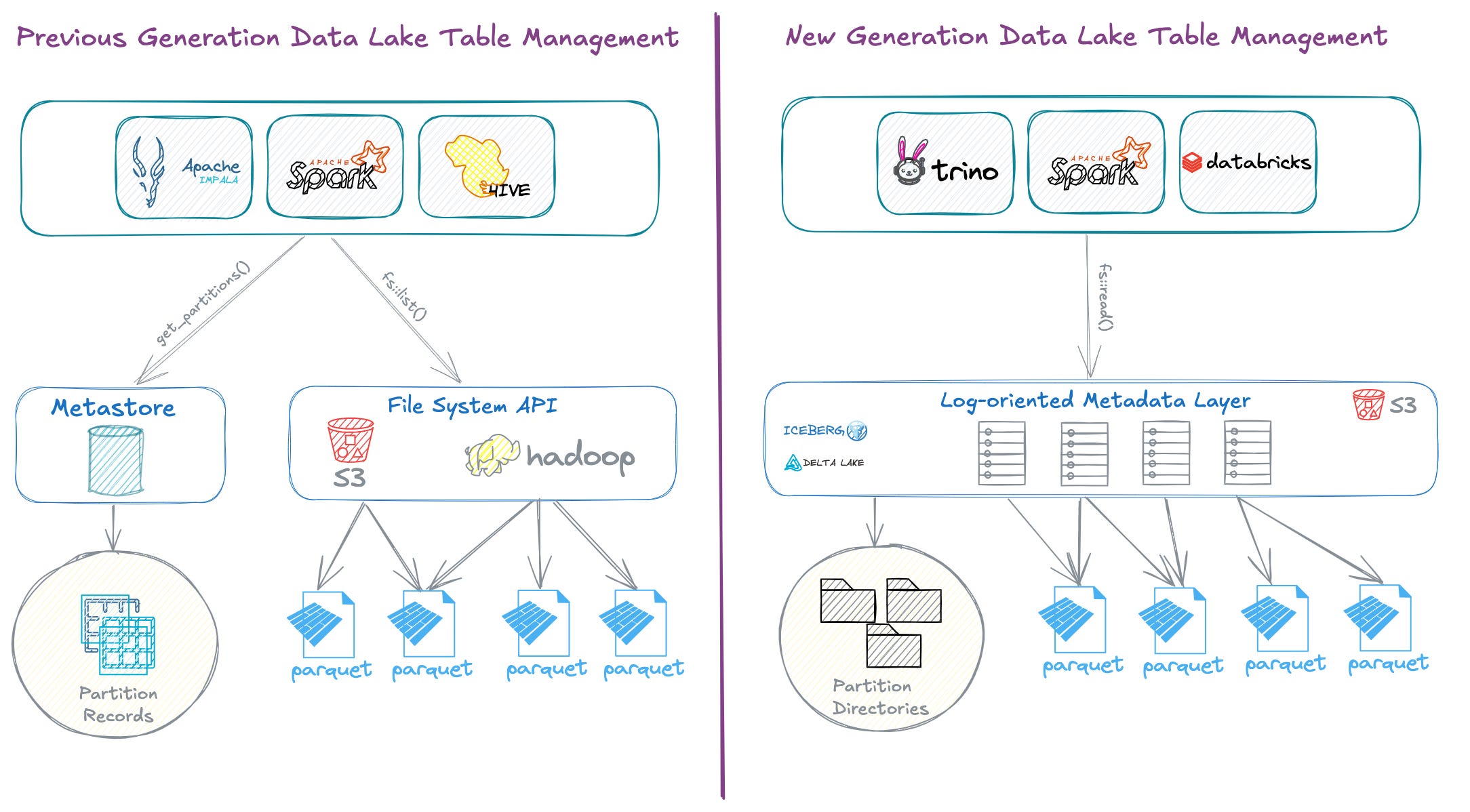
In this article we will explore the overall design and architecture of the metadata layer on these modern table formats to better understand how they are structured and managed.
Metadata Structure
The design and organisation of the metadata layer can have a significant impact on the metadata access strategy during query planning, which in turn can affect overall query performance. A straightforward approach involves storing all metadata for each dataset in a dedicated special directory which you could think of it as a sub-table inside the main table.
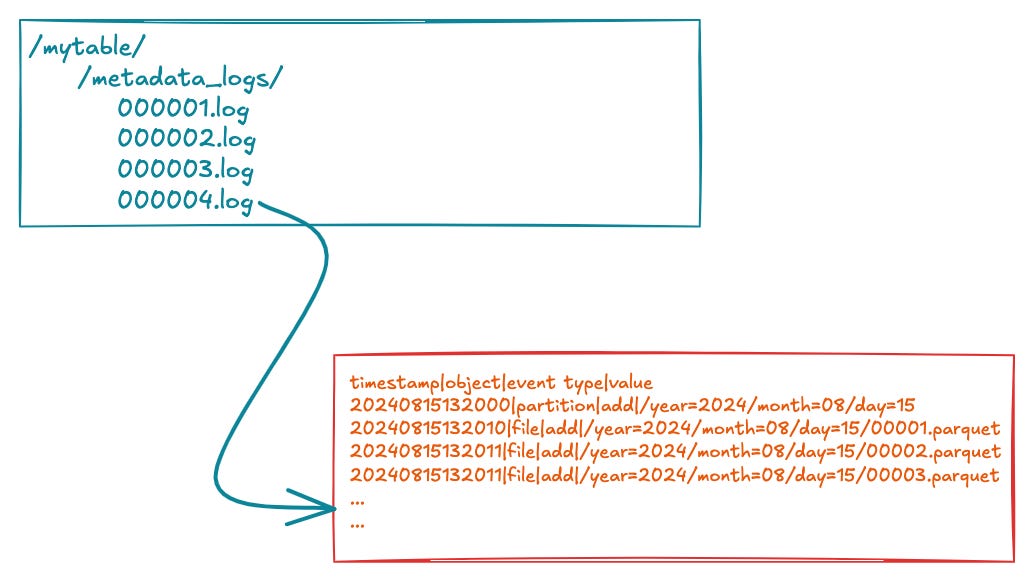
This sub-table, containing the metadata records in a semi-structured log files, is stored alongside the actual data files within the data lake, typically as a subdirectory directly under the root dataset path.
Lets say we have a table called mytable, directly under the main path we can store our special sub-table called ../metadata_logs as a subdirectory containing the metadata logs.
/mytable/
/metadata_logs/
000001.log
000002.log
000003.log
000004.logTogether with the data files and partitions the overall structure of a simple table would look like the following:
/mytable
/ts=2024-08-01/20240801-01.parquet
20240801-02.parquet
20240801-03.parquet
/ts=2024-08-02/20240802-01.parquet
20240802-02.parquet
/metadata_logs/000001.log
000002.log
000003.log
000004.logAt the time of the query engine would scan the available metadata logs stored under the ../metadata_logs subdirectory during query planning phase to build a list of actual data partitions and files to be scanned.
How is this more efficient?
This design fundamentally eliminates the dependency on the underlying storage metadata API for performing directory (i.e., partition) and data file listings during the query planning phase—a process that often incurs higher latency and can become a significant performance bottleneck in large-scale data lakes.
Instead, the approach leverages the storage's fast sequential I/O capabilities to scan and read a few metadata log files end-to-end. This method offers significantly better performance compared to gathering file lists and statistics by issuing many LIST API calls.
These API calls are often subject to throttling and limits, typically returning only 1,000 objects per call on cloud platforms. This can be particularly problematic when dealing with potentially hundreds of thousands of files and numerous partitions in large-scale data lakes.
In a typical Hive or Spark workload that needs to perform a query on a table containing couple of years of data partitioned by date, the engine would have to make thousands of API calls for gathering details of all available partitions and their data files in order to perform split planning for assigning work to each worker.
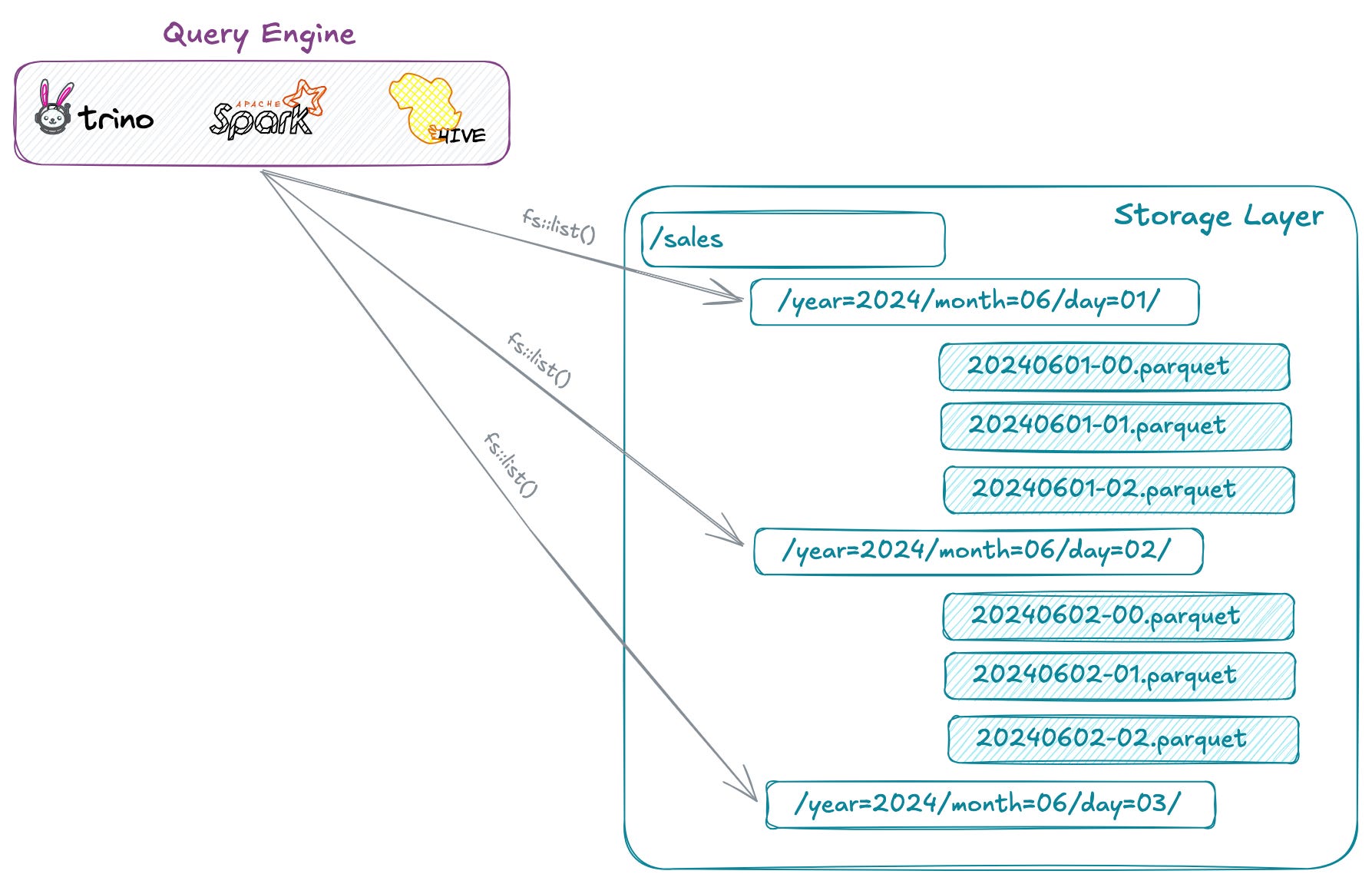
However, if all the details of all data files and partitions are stored in few metadata log files, the engine can quickly scan the logs using fast sequential I/O to identify all the required objects, which is substantially faster.
Based on industry benchmarks, the new approach significantly reduces the directory and file listing latency compared to direct listing using the underlying storage API such as HDFS and S3.
Hudi's experiments shows 2-10x improvement in listing latency compared to S3 over large datasets.
Hierarchical Metadata Organisation
Another way to structure the metadata layer is by using a hierarchical approach. In this method, the lower levels of the hierarchy consist of files that store metadata about specific sets of data files. As you move up the hierarchy, index files aggregate metadata from the layers below, effectively serving as a table index.
In Apache Iceberg’s layered design, at the lowest level, each metadata file (refered to as manifest file in Iceberg terminology) would track a subset of the available data files for a table.
In the second layer, a Manifest list file contains a high-level index of the collection of the manifest files in the lower layer. It stores essential details such as the current snapshot ID, the locations of the manifest files, and partition boundaries.
Finally, a master Metadata File sits at the top of the hierarchy as shown below, storing a high-level snapshot view of the table's metadata. This file is referenced by the table's metadata pointer attribute and is regenerated whenever there is a change in the table's metadata.
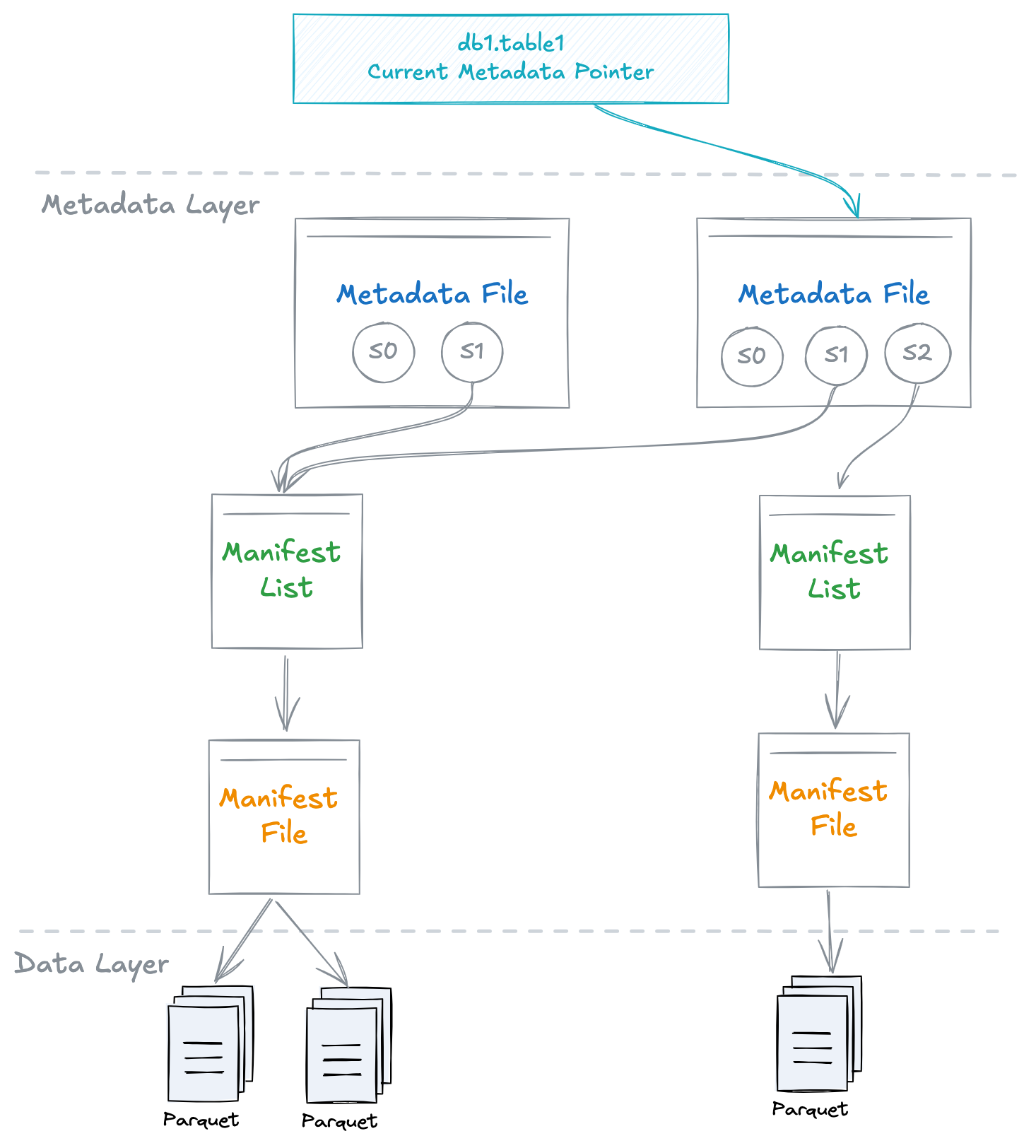
Importantly, this hierarchical structure of metadata does not need to correspond to a physical hierarchy in terms of file organisation. For example, in Iceberg, all metadata files are kept under a single metadata directory, regardless of their hierarchical relationships
Why would Iceberg structure the metadata in this way?
The purpose of designing a hierarchical indexing structure in Apache Iceberg is to optimise metadata lookup performance by minimising the number of metadata files that need to be scanned during query execution.
By organising metadata in a more structured and layered manner, the system can quickly locate relevant data, leading to faster query response times. However, the trade-off is a more complex metadata structure compared to the simpler, flat design.
Metadata Storage Models
The storage model is concerned with how the metadata records are managed in the metadata log files.
An important design factor to consider is that due to the immutable nature of the underlying storage layer, metadata update events—such as the addition or removal of data files—cannot simply be appended to the existing metadata files. As a result, for new metadata update operations a new delta file must be generated.
To ensure storage and I/O efficiency, the frameworks typically perform a periodic background compaction operation. This process merges smaller delta logs into a snapshot base log. At any given point in time, the table's metadata is a combination of the last snapshot log and any new delta logs that have not yet been compacted.
There are two main storage models currently implemented by the open table formats for storing and managing table's metadata:
Log-structured Metadata Model
This is the simplest implementation technique where all metadata changes are treated as immutable, ordered events stored sequentially in transactional event logs.
This approach essentially applies the event sourcing pattern to capture all state changes at the file level, recording them in transactional logs that are stored alongside the actual data files similar to WAL implementation of the database engines.
Files and partitions serve as the unit of record for which the metadata layer tracks all state changes, capturing these changes within the event log. To rebuilt the current state of the table, all records in available logs are scanned sequentially from top-to-bottom.
Instead of using an unstructured format, semi-structured formats like JSON can be employed to provide better schema support and flexibility, while being both human-readable and easily parsed by machines. This is the approach used by Delta Lake, where transactional metadata logs are stored in JSON format.
Table-oriented Metadata Model
In an object or table-oriented metadata design, the framework treats table metadata—primarily dataset partitions and file listings—as a special "table" stored in a more structured file container, similar to how it handles the base table containing the actual data files.
The key difference from the framework's perspective is that this special table is used to manage metadata events rather than actual data records.
What are the trade-offs between the two models?
Compared to a log-structured implementation, a table-oriented metadata design is a relatively more closed and abstract approach to managing the metadata layer in open table formats.
In a log-structured approach, transactional logs are the first-class citizens of the metadata layer, directly accessible by the framework as well as other engines and users. In contrast, the table-oriented design uses a logical table as the access point for all metadata operations, abstracting the underlying metadata log files.
A Combination of the two models are used by the existing frameworks. Apache Hudi heavily relies on optimised table-oriented metadata management using HFile structured file format. The metadata table is internal to the framework and not exposed so much to users or clients.
On the other hand, Delta Lake and Apache Iceberg follow more open log-oriented design offering the additional benefit of supporting metadata streaming and event-based ingestion primitives out of the box.
Metadata Index Files
In this section, we will explore the format of the different metadata files used in the metadata layer, and the how the table events are captured and managed.
Data Files Index
A data file index is a type of manifest file used to maintain the list of active data files associated with a table.
As mentioned earlier, the goal is to eliminate the need for performing recursive storage metadata API calls to gather the list of data files. A file index can also help reduce cost on cloud object stores by significantly lowering the rate of API calls required during reading and writing operations.
Implementing a file index for a non-partitioned table is relatively straightforward. A sequential log file at the base table level can be used to insert new filenames—either with full or relative paths— to a metadata log. During the query planning phase, the generated log files can be scanned from start to finish to identify all active files belonging to a table.
For capturing storage-level or filesystem state changes we need to consider two main filesystem object types, that is files and directories (i.e partitions) with following possible events:

In a most simple form, the files index can be implemented with following fields in a WAL (Write Ahead Log) type file:
timestamp|object|event type|value
20231015132000|partition|add|/year=2024/month=08/day=15
20231015132010|file|add|/year=2024/month=08/day=15/00001.parquet
20231015132011|file|add|/year=2024/month=08/day=15/00002.parquet
20231015132011|file|add|/year=2024/month=08/day=15/00003.parquetImplementation of Data Files Index
Delta Lake manages file listing information at the base level of the table using a combination of a base Parquet file and additional JSON transaction log files. All file-level updates are committed to the JSON files at the time of writing.
Apache Hudi maintains all file listing metadata in a single base HFile, stored under the .hoodie/metadata/files path. The HFile is partitioned into four sections: files index, column stats, bloom filters, and record level index. The Files index contains two types of records: one for adding new partitions and another for adding new files.
Following shows an example of adding a new partition key 2024-08-01 with a new file file10.parquet:
-- Insert a new file record (Type 2):
{"key": "2024-08-01", "type": 2, "filenameToSizeMap": {"file10.parquet": 12345, isDeleted: false} }
-- Insert a new partition record (Type 1):
{"key": "_all_partitions_", "type": 1, "filenameToSizeMap": "2024-08-01": 0, isDeleted: false} }Why Hudi selected HFile as the metadata file format?
The motivation behind selecting HFile file format is that even for very large datasets containing thousands of partitions and millions of files, the expected compressed and encoded HFile would be within a manageable size, typically hundreds of megabytes and less than a gigabyte.
Additionally, having fewer metadata files to scan can significantly improve performance during read operations. Consequently, HFile has been selected for managing both base and log files within the metadata layer by Hudi.
Hudi claims that based on experiments, HFile performs better than Avro and Parquet (Used by Delta and Iceberg) for point lookups (10x to 100x improvements) over large number of metadata entries.
Snapshot File Index
Periodically, a log checkpoint operation is performed on a specific set of delta log files to summarise the log up to that point into a snapshot file. This process eliminates duplicate entries and retains only the latest list of active partitions and files. As a result, the checkpoint file represents the state of the table at a specific point in time.
In Delta Lake, the snapshot file is maintained in Parquet format. To compute the current table state in terms of active files and partitions during a query, the latest snapshot Parquet file, along with any subsequent JSON transactional logs, must be consulted to obtain the current list of active files in the table.
Example of an ‘add’ action log record in Delta:
{
"add": {
"path": "date=2024-08-10/part-000...c000.gz.parquet",
"partitionValues": {"date": "2014-08-10"},
"size": 841454,
"modificationTime": 1512909768000,
"dataChange": true,
"baseRowId": 4071,
"defaultRowCommitVersion": 41,
"stats": "{\"numRecords\":1,\"minValues\":{\"val..."
}
}Managing Deletes
When files or partitions are deleted, the file index needs to track these changes and remove the corresponding listings. Due to immutable nature of the log files, the file index cannot be simply updated to remove the entries.
A common approach to handling deletions is the use of a delete tombstone method, where a new record with a delete marker is inserted into the metadata log. This marker is then used during query time to identify and filter out the deleted files.
Additionally, a background compaction operation can be employed to clean up the file index by removing duplicate keys and older versions of records, thereby maintaining an up-to-date and efficient index
Hudi uses a special field in each record inserted into the HFile index called ‘isDeleted’ as the delete tombstone hint:
{"key": "2024-08-12", "type": 2, "filenameToSizeMap": {"file20.parquet": 65432, isDeleted: true}}Delta Lake follows similar delete tombstone technique, however unlike Hudi which uses an attribute in the inserted log as a delete hint, Delta Lake uses a distinct metadata action for the transaction log called ‘remove’ when committing a new log to the transaction log.
During log compaction process previous duplicate ‘add’ actions are eliminated but their ‘remove’ actions are maintained until the retention period has expired.
Example of a ‘remove’ action log record in Delta:
{
"remove": {
"path": "part-00001-4.parquet",
"deletionTimestamp": 1515488765783,
"baseRowId": 1171,
"defaultRowCommitVersion": 11,
"dataChange": true
}
}Unlike the previous two implementations, Apache Iceberg maintains a separate manifest file which only contains deleted files logs. At read time, the delete manifest files are scanned first during query planning to identify which files to exclude during query planning phase.
Column-stats Index
An optimisation feature of open table formats is the storage of table statistics, such as column min-max values, in a separate metadata structure to facilitate faster query planning.
The goal is to eliminate the need for the conventional, expensive per-object statistics gathering during the query planning phase. This typically involves scanning the footer sections of all Parquet or ORC data files to prune irrelevant data files. This approach is not scalable when dealing with a large number of partitions and data files, as a large query would require scanning each serialised file's footer separately, resulting in numerous I/O calls.
By storing column statistics in a separate, efficient metadata index file, query engines can leverage faster and more efficient sequential I/O to perform the necessary query planning, significantly improving performance
Implementation of Column-Stats Index
Delta Lake supports storing per-column statistics within the same JSON-based delta log files, using a nested structure within the main data file metadata record. This structure mirrors the schema of the actual data by storing each file's minimum and maximum statistics.
For example, if the schema contains columns like product and price, the ‘stats’ key in the metadata structure of the delta log would resemble the following format:
{
"add": {
"path": "date=2014-08-10/part-000...c000.gz.parquet",
"partitionValues": {"date": "2024-08-10"},
...
"stats":{
"numRecords": 10,
...
"minValues": ["product": "book","price": 15],
"maxValues": ["product": "book","price": 23]
}
}Apache Iceberg's design for storing both table and column-level stats is similar to Delta, by storing each type of statistic such as column min and max values, in a separate field of array type, inside the main data_file metadata record of manifest files.
To make the column stats object more compact, Iceberg stores the column id as the reference instead of using the column name
"value_counts": [
{
"key": 1,
"value": 34535
},
{
"key": 2,
"value": 54321
},
{
"key": 3,
"value": 5566712
},
]Since version 0.11, Apache Hudi introduced a multi-modal index, which also stores column-level statistics within the same metadata table, specifically in the HFile metadata log.
These statistics are stored under a separate partition (i.e., key) as a stand-alone partition called column_stats. By keeping the keys sorted, this structure leverages the locality of all records for a particular column, enhancing query performance and efficiency.
Since the statistics are stored under a separate key, each record must include the filename and path fields which can be seen as an extra overhead compared to Delta and Iceberg implementation. The current supported statistics include minValue, maxValue, valueCount, and nullCount.
Unlike Delta and Iceberg, which store statistics differently, Hudi uses an additional field, ‘isDeleted’, as a marker to indicate whether a column stats record is valid or not, due to the stats being stored under a separate partition.
Advantage of combining different index types in a single object
Using a single index file to manage both types of metadata (files and column stats) offers the advantage of reducing both metadata file management complexity and I/O overhead. Additionally, employing a single object with nested structures to store additional metadata allows for the use of a unified schema to manage the table's metadata.
This approach eliminates the need to manage multiple schemas for each metadata type, simplifying overall metadata management. Furthermore, there is no need to separately track the statistical metadata of deleted data files, as the unified structure inherently handles this
Partition Management
As open table formats represent an evolution of data lake formats by introducing a metadata abstraction layer on top, they inherently support conventional hierarchical partitioning schemes on data lakes.
Unlike traditional Hive-style partitioning, where partitions are physically represented by a directory structure, open table formats treat these directories as configurations.
These configurations provide instructions to the processing engine on how to structure the data and maintain the relationship between data files and the projected structure. The partitions themselves are stored and tracked in the metadata layer, either as a separate structure (index) or embedded within the entries of the main file index log.
By managing the mapping of files to partitions in the metadata layer, this design effectively decouples physical partitioning from logical partitioning at the table level.
This decoupling allows for greater flexibility, supporting partition evolution, partition consolidation, and the possibility of utilising different partition schemes within the same dataset.
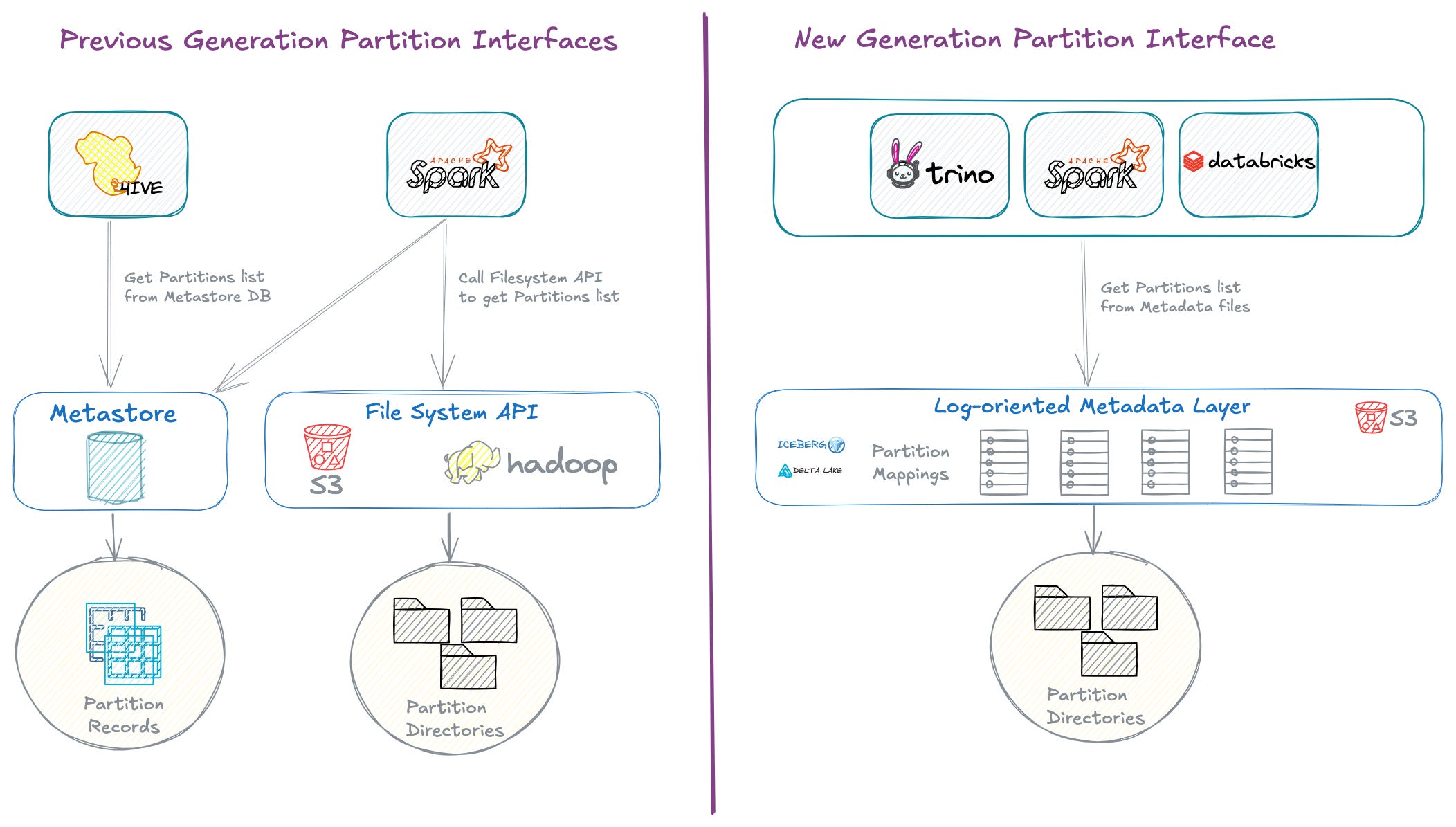
Moreover, this approach abstracts the partitioning scheme from ETL and data ingestion pipelines. It eliminates the need for these pipelines to be aware of the table's partitioning scheme, allowing for either explicit or dynamic partitioning in SQL transformation statements.
This abstraction also mitigates some of the traditional trade-offs, such as the challenges associated with using event time for partitioning, particularly in handling late-arriving events.
Another notable technique employed by table formats like Apache Iceberg involves automatically generating and using hash-based paths in cloud object stores. This strategy distributes files within a partition across multiple prefixes, helping to avoid throttling and performance issues when scanning a large number of files, especially due to per-prefix call limits.
Implementation of Partition Management
In its simplest form, a new log entry can be added to the file index for each partition added to the base table within a log-oriented structure. This approach is akin to how Delta manages metadata updates.
Specifically, Delta captures any changes to a table's metadata—such as schema modifications and updates to the partitioning scheme—within a ‘metaData’ action type (a struct) as an entry in Delta's transaction logs. The ‘partitionColumn’ attribute within this record captures the current partition columns of the table, ensuring that the metadata reflects the most up-to-date structure.
Here’s an example of the ‘metaData’ action entry in Delta’s log files:
{
"metaData":{
"id":"af44c3a7-abc1-4a5a-a3d9-33d65ac711ba",
"format":{"provider":"parquet","options":{}},
"schemaString":"...",
"partitionColumns":["process_date"],
"configuration":{
"appendOnly": "true"
}
}
}In an object-oriented metadata structure, all partitions can be encapsulated within their own object (struct) in the main index file. This method is employed by Apache Hudi, where table partitions are tracked by inserting a new log entry into the base HFile index with a specific key, ‘_all_partitions_’.
This key aggregates all partitions within a single object, making it easier to manage and track the partitions at the table level. By using this approach, Apache Hudi efficiently maintains an up-to-date record of all partitions within the dataset.
{
"key": "_all_partitions_",
"type": 1,
"filenameToSizeMap": "2024-08-10",
"isDeleted": "false"
}Apache Iceberg also stores partitioning details in the top-level metadata JSON file under its own ‘partition-specs’ key. This key encapsulates the partitioning scheme used by the table, detailing how data is logically divided.
{
...
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ {
"name" : "process_date",
"transform" : "process_date",
"source-id" : 2,
"field-id" : 1000
} ],
}Apache Iceberg goes a step further by storing additional partition statistics such as record count, file count, total size, and delete record count within its metadata. These statistics can significantly enhance query planning and cost-based query optimisation.
Additionally, these statistics are used to facilitate Dynamic Partition Pruning, a technique that reduces the amount of data scanned during queries by eliminating irrelevant partitions early in the query execution process.
What has been presented here forms the foundation of the architecture behind the metadata layer in modern open table formats. However, there are many additional details and advanced features that these systems offer. For those interested in exploring further, the official documentation of the covered projects are a good source of reference.