
Internal Storage Design of Modern Key-value Database Engines [Part 2]
Overview of the physical storage design implemented by many modern popular key-value stores such as Amazon Dynamo DB, Apache Cassandra, Riak, ScyllaDB, LevelDB and RocksDB

In the first part of this blog series I presented an overview of key-value store data model used by many modern key-value stores in the market, presenting a simple physical storage abstraction using a hybrid two-level memory hierarchy model. In the first part I covered a preliminary model for the on-disk storage structure using immutable log segments. At the end we were presented with the limitation of sequential log segments and the high cost of key lookup.
In this part I will introduce a major optimization for the on-disk data structure, as well as covering the in-memory component.
Sorted Segments - SSTables
We can present an improved version of our simple on-disk log-structured segments with one big difference in order to overcome the discussed limitations, that is to have the key-value records sorted by key in segment files. The sorted segment files was proposed by Google BigTable original paper design published in 2008 [1] in which such sorted segments are called SSTable standing for Sorted String Table.
Therefore main different between SSTable file and normal segment presented in the previous section is that SSTables are log segments which are sorted by key. Sorted log segments would provide many advantages over simple non-sorted log files such as:
Facilitating and optimizing for range query access pattern.
When using additional In-memory Hash Map Index, it doesn’t require to keep reference to all the keys (therefore its more manageable) since by being able to lookup an approximate key in the index, scanning the segment file to find the close by sorted key is still efficient and fast.
As it will be explained later for storage optimization purpose, merging SSTable segment files is efficiently done with bulk read and write of the files, using merge-sort algorithms as merge-iteration preserves order of keys.
However since keys have to be maintained sorted, new writes cannot simply be appended at the end of the file. Random insert is also not feasible since it would require sequential scan to find lower and upper bound keys in the segment, as well as rearranging the subsequent records, and updating in-memory index offsets for affected keys. Therefore another mechanism is required to maintain SSTables on disk with keys sorted in each segment without the mentioned complexities or losing the advantages of sequential I/O performance.
Now the question is how can we achieve this by both keeping the records sorted by key in the segment files and at the same time avoid any random seeks to reposition records in order to preserve the advantages of only relying on sequential I/O ?
Google solved this problem in his BigTable design which will be discussed but before that lets look at the SSTable file structure in more detail.
Internal Structure of SSTable segments
The internal structure of SSTable files as proposed by BigTable design includes the following features:
Unlike plain segment files, internally the SSTable may comprise of fixed-size blocks (64K size by default in BigTable).
Smaller block sizes such as 8K are more efficient for applications with high rate of random reads because of the overhead of network transfer and SSTable parsing [1].
Block indexes inserted at the end of each block can be used to perform faster key lookups to find a target block using the index loaded in memory.
Compression can be applied on the block level which would provide the benefit of not requiring to decompress the entire SSTable when only reading some blocks, therefore providing faster performance which being less space efficient.
Caching can be applied on the block level to improve sequential reads

Next the In-memory storage structure of our two-level storage hierarchy will be presented.
In-memory Storage Structure
The storage component that resides in memory is essentially served as buffer for the purpose of deferring writes to segments to optimize and reduce the cost of random I/O by making write operations sequential with a single pass.
In the previous section we were presented with the challenge of keeping keys sorted in SSTable files on disk, without having to perform any random I/O operations to move and shuffle keys when inserting new one. This is where the in-memory buffer comes to rescue. Due to challenges of keeping keys sorted on SSTable files and to take advantage of the sequential I/O efficiency for writes, it’s more efficient to perform and maintain key-value entries sorted in-memory using available efficient data structures, and periodically flush to buffer to produce sorted segment files (SSTable) on disk.
Therefore by taking advantage of fast and efficient in-memory data structures, we can have the newly written records sorted by key before flushing them to on-disk data structure.
This in-memory data structure is named Memtable in Google Bigtable design [1]. To provide a short definition of Memtable, it is essentially an in-memory sorted key-value buffer which can be used in key-value storage engine to sequentially store sorted records by key in segments (SSTables) on persistent storage.
Data Lifecycle
Now with introduction of the two main components of the storage model, that is SSTable and Memtable, we can present the full data lifecycle design.
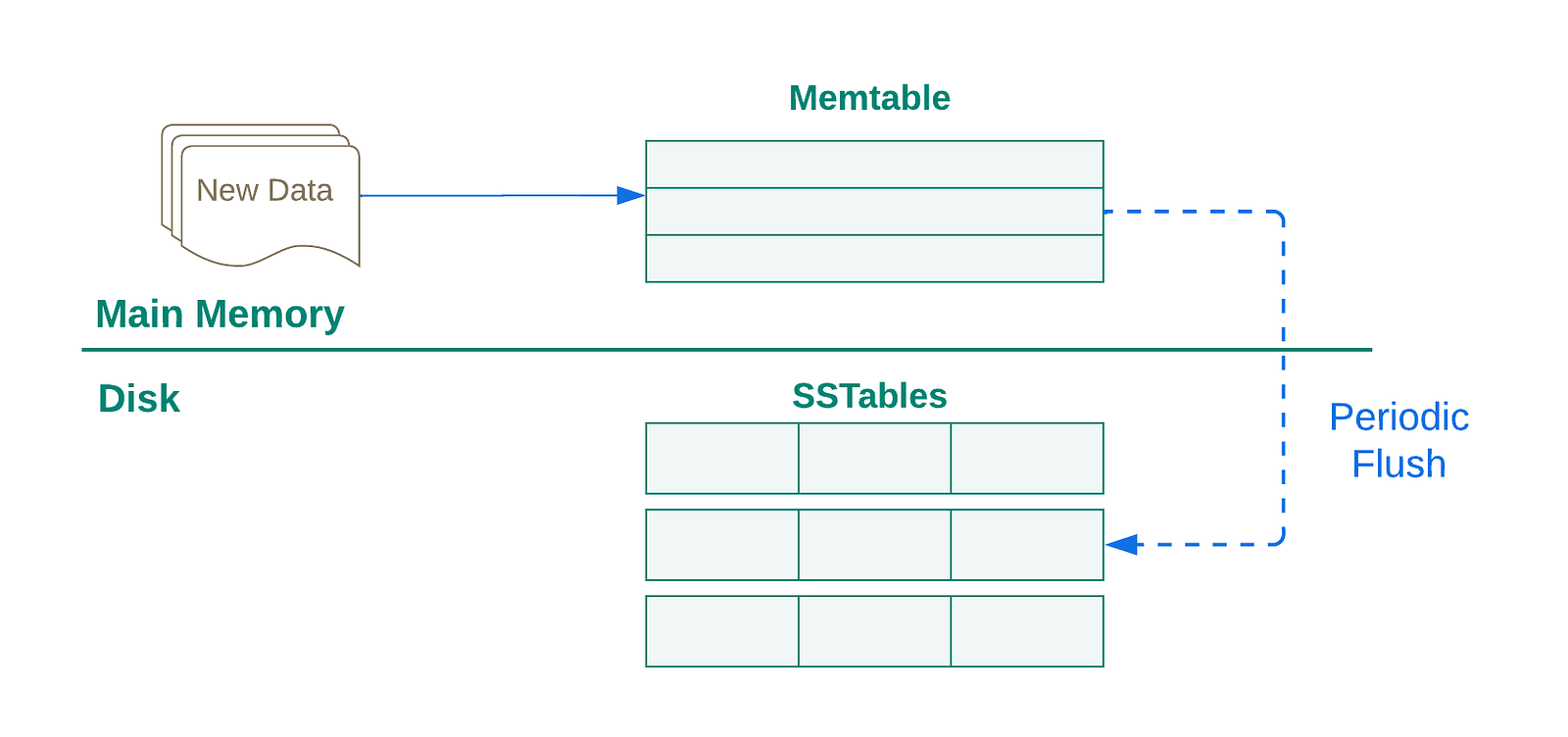
The Process is as follows:
As New data arrives it is inserted into the Memtable sorted data structure.
Memtable needs to be periodically Flushed to disk-resident structure once it reaches a specific size threshold.
Before flushing, the current Memtable must be switched and a new Memtable has to be allocated to become the target of new incoming writes.
The closed Memtable remains accessible for reads before being flushed completely at which point it is discarded in favour of the new Memtable.

In order to provide durability for in-memory data and avoid data loss in an event of system crash or any other type of failures, an extra sequential commit log also referred to as WAL log is employed similar to relational engines, to preserve new changes on persistence storage for the purpose of recovery.
The commit log gets trimmed with flushed content being discarded once the flushing process has been completed successfully.

Buffer Flushing and Checkpointing
Flushing is the process of synchronizing and committing changes from in-memory buffers such as Page Cache or Memtable in this case, to the primary disk-resident storage specially in storage engines having two-level memory hierarchy (main memory and disk). Due to limited size of RAM flushing is inevitable as the buffer cannot keep growing in perpetuity.
In databases using Page Cache, the dirty pages are periodically flushed back to disk during Buffer to Disk Checkpoint process or cache eviction process to make the changes durable. In the presented storage model the writes buffered in Memtable are flushed to disk periodically when the Memtable reaches a specific size threshold. While after flushing the page cache to disk the flushed in-memory pages are not necessarily evicted from the cache, in this case the Memtable buffer is emptied when flushed to free up space for new updates.
Checkpoint process coordinates the Buffer Flushing of unpersisted changes from in-memory buffer to the primary disk-resident storage. This process is usually run periodically in the background. The updates that were successfully flushed from the Memtable can be discarded from the commit log. Therefore checkpoint process also acts as a watermark for logging process to indicate that the records up to a specific mark have been successfully persisted and no longer required in the commit log.
Flushing Frequency Tradeoffs
The longer the flushing process is postponed, less disk access is need at the cost of more memory being required and possibly longer crash recovery. If flushing is performed more frequent, less memory is needed at the cost of more frequent disk accesses.
Data Structure
Popular in-memory data structures which can be used for maintaining the in-memory sorted key-value records include Red-black trees, (2–3) trees or AVL trees [2].
LSM-Tree
The storage model that has been presented so far is essentially what Log-structured Merge Tree or LSM-Tree entails as a hybrid (multi-component) data indexing technique first introduced by Patrick O’Neil et al [2] in 1996 to propose a more efficient on-disk indexing structure than the common algorithms and methods in commercial databases mainly B-Tree.
The main goal was to find a more I/O efficient mechanism for indexing history tables with high insert rate and volume in transactional systems, since using existing popular B-Tree structured deemed costly in terms of I/O efficiency. Updates on traditional B-Tree used in relational databases usually involves multiple random read and writes. Therefore the main goal of development of LSM-Tree model was to reduce the cost of I/O related to B-Trees specially for heavy-write use-cases.
In general the presented LSM-Tree is more suitable when the rate of writes and inserts are a lot higher and more common that lookups [2]. However with extra optimizations used by various key-value stores the lookup efficiency has been improved.
It must be emphasized that the original LSM-Tree design doesn’t include the components such as SSTable presented earlier. Google BigTable improved the model by introducing SSTable as the on-disk data structure and forcing the records to be sorted by key in the in-memory component (Memtable) before flushing to disk.
In the next part, one of the major background data operations to manage the on-disk data in the presented LSM-Tree design will be discussed.
References
[1] Chang, Fay, et al. "Bigtable: A distributed storage system for structured data." ACM Transactions on Computer Systems (TOCS) 26.2 (2008): 1-26.
[2] O’Neil, Patrick, et al. "The log-structured merge-tree (LSM-tree)." Acta Informatica 33 (1996): 351-385.